Credit Card Fraud Detection using Apache Spark Streaming and Kafka

Fraud detection touches every company in many different industries including banking and financial sectors, insurance, government agencies and law enforcement, and more. It’s is a billion-dollar business, and fraud is increasing every year. Although , I have considered a simple use case, it should provide an understanding of how Hadoop and Spark Streaming are used to provide a solution for fraud detection. The blog provides some suggestions regarding real-time processing and exploratory analysis, but specific machine-learning algorithm is not covered.
Introduction
Fraud Cases related to credit card have risen exponentially over the past few years. Unfortunately, fraud is one of the main challenges consumers have to deal with every day. There are different categories of scams with credit card transactions, and big data allows financial institutions to approach fraud differently. Big data can help by identifying suspicious activities, possible fraud attempts and study the historical data to predict anomalies.
Carly Fiorina says,
“The goal is to turn data into information, and information into insight.”
Let’s take an example of playing cricket, where the batsman has to detect the arrival of the ball and react accordingly. Similarly, other players in the field will have a collective response to the ball as the batsman hits it. During the game, there is no time think, and the player’s reaction on instinct from years of practice. They may notice that a particular aspect of their game is consistently weak and work on improving it, so during the game, they can instinctively perform better.
Fraud detection is the architecture of different sub-system, which work together to detect anomalies in the stream of the events.
Technologies Considered
Apache Kafka is used for ingestion and Apache-Spark Streaming which helps to use the Spark APIs for processing. The data is stored to HBase or Kafka consumers. Tools like Apache Zeppelin Notebook is suggested for visualization. Spark Streaming , HDFS , HBase and Kafka, all can be run in clusters which are open source tools, and they are built for redundancy and scalability. Flume is also used as an ingestion tool, but Kafka shines in terms of scalability and has demonstrated the ability to handle tonnes of events .
More about the use case :

Credit card transaction can be captured over time based on the behavior of the cardholder’s spending incidents. The events are stored as transaction history which would be used to analyze the possible detection of fraud. Apache Spark Streaming and Apache Kafka work pretty well in capturing such incidents real time. Furthermore, the ecosystem is capable of handling vast and a variety of data with good throughput and low latency. Spark API can be used to develop for prediction model, and it works well with Kafka for data streaming. To make simple, let’s characterize the prediction of fraud with the amount spent by the cardholder to be high/low/medium and location of the card holders. The mining algorithms in Spark can use this criterion.
Ecosystem Overview
A a brief introduction of the Apache Kafka and Spark Streaming components. Further in-depth knowledge is found on the web.
Apache Kafka
Kafka supports parallelism and is a distributed message bus; its primary use is reliable message delivery architecture. Kafka uses a system of producer and consumer messaging. The processes that are subscribed to topics and take the published messages are the consumers. Kafka, is a distributed system and runs in a cluster. Each node in the cluster is called a Kafka broker.
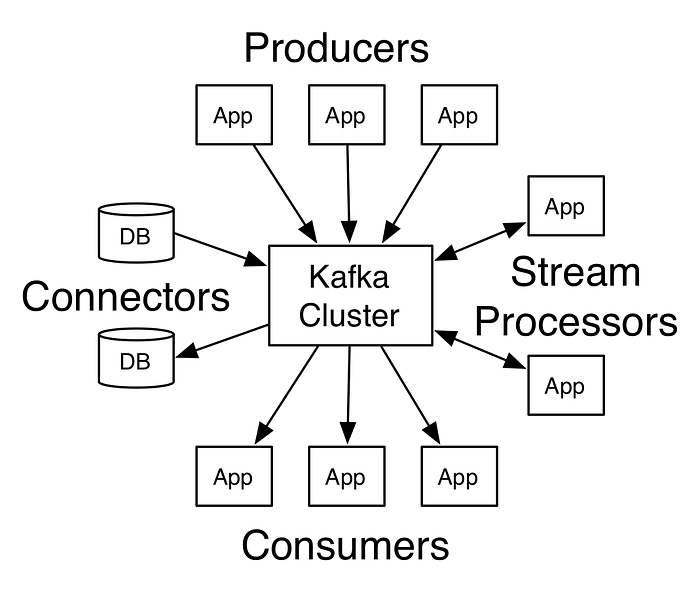
The data to Kafka is fed in by various sources as seen in the first diagram. Kafka stores a stream of records in topics, with each topic consisting of a configurable number of partitions for throughput and scalability. The partitions of a topic are critical for performance and an upper bound on the consumer parallelism. Let’s say the topic has N partitions and applications can only consume the topic with n threads in parallel.
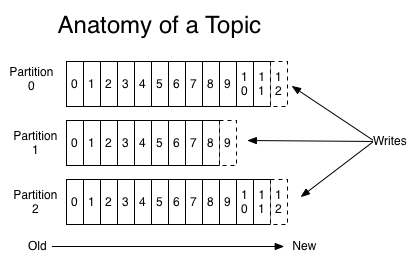
In this case, the credit card transactions events are ingested to Kafka, and these events are topics which are read and written accordingly. The credit transactions are enriched with card holders details stored in historical data and predicted as a not fraud.
Apache Spark Streaming
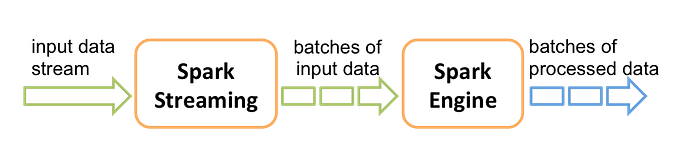
Apache Spark is a framework for batch-processing, like data analytics on distributed computing clusters like Hadoop. Spark Streaming can process structured and unstructured data in Hive, HDFS, Flume, Kafka, HTTP, Twitter, etc. Spark Streaming takes advantage of the power of Spark RDDs and combines it with reliability and exactly once semantics to provide high throughput. Spark reads straight from a file and converts it to a Resilient Distributed Dataset (RDD). An RDD format will allow making use of the mlib statistics package of Spark, that takes the RDD as input and applies useful statistical operations such as mean, variance, max, min, etc.
Spark Streaming receives data streams and splits data into batches. After the division, data is processed by the core of Spark which will generate the final stream of results in batches from the specified interval of time which is windowing. The fact that DStreams contain RDDs make possible that Spark Streaming have a set of transformations, available on DStreams. These transformations are like those available on the typical RDDs of Spark.
Data processed in Apache Spark:
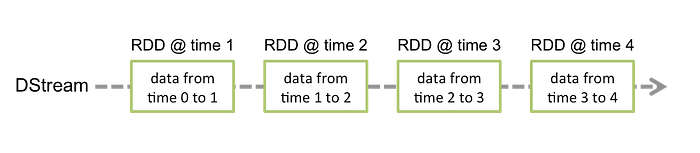
When these streams of the data come to Spark Streaming as DStrems, they are sequenced internally as RDDs. The RDD operations are performed in parallel where the credit card data is parsed to get the necessary information. Events related to fraud are published to fraud topics, and likewise, non-fraud events are published to enrich topics.
The Big data fraud detection techniques or mathematical models analyze the data to find the relationship between the historical data and the data which is learned over the period. The techniques will help in extracting meaningful evidence of frauds from large data sets.
In this example, let consider the credit card holder is from Bangalore and all the transaction is above the spending limit, and it’s made in the different city. The stream of data injected through the Kafka to various topics and is processed in the Spark engine and analyzed to detect fraud which is written to the fraud topic. If the transaction is over the limit of regular spending or the transaction is made in a different city, transaction is written to the fraud topic.
Each topic can have multiple Kafka consumers; this allows processing the same message by various Kafka consumers for different purposes. In this case, we have taken the fraud details to published to the Kafka consumers. Furthermore, the enriched topic is also analyzed to learn customer behavior and stored in HBase or any other data store.
The whole processes is a continuous process to understand normal and abnormal behavior and then act accordingly. The data stored in the HBase can be used for reporting and visualization. Apache Zeppelin is one of them, which helps to create a data-driven & interactive user interface for reporting, and visualization. Zeppelin notebook allows integration with Spark Streaming and Kafka.
Challenges and Advantages
The biggest challenges with big data or the Hadoop ecosystem is the many distributions, profile storage, ingestion frameworks, caching options, processing engines, etc. Though it provides the distinct advantage of open source and 4 Vs -volume, variety, velocity, and veracity, it might be difficult to choose the components to build the ecosystem.
Apache Spark and Kafka are taken as examples here to supports reliable ingestion of streaming data, the ability to perform a transformation on streaming data in flight using processing and analyzing the history of the data. Spark Streaming supports micro batch based architecture where stream of data processed in the window of the time interval. Most importantly it supports large ecosystem.
CONCLUSION
The Hadoop ecosystem is a healthy collection of different tools for high performance, large volume, various formats of data, platform to create custom solutions , distributed and open source which enables easy adoption.
Apache Spark is an open-source processing engine build on top of the Hadoop system. It offers multiple language support, and easily it can be integrated with various infrastructure tools and Hadoop distributions . The simple credit card use case is considered to see how the Spark streaming technology and Apache Kafka can be used to build the solutions.
REFERENCES
- https://kafka.apache.org/
- https://spark.apache.org/docs/latest/streaming-programming-guide.html
- Hadoop Application Architectures: Designing Real-World Big Data Applications
- Except for the first diagram, the other diagrams are from Apache Kafka and Apache Spark Streaming.

